Multiplayer AlphaZero
Por um escritor misterioso
Last updated 16 junho 2024


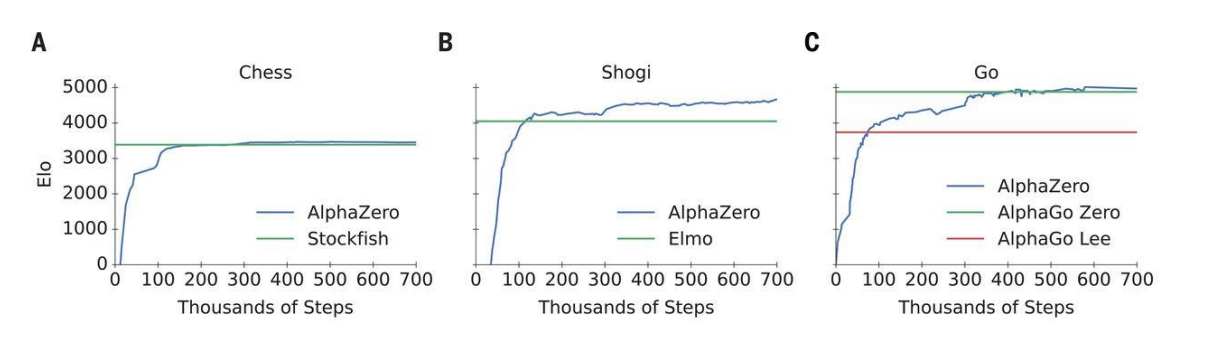
Training AlphaZero for 700,000 steps. Elo ratings were computed from

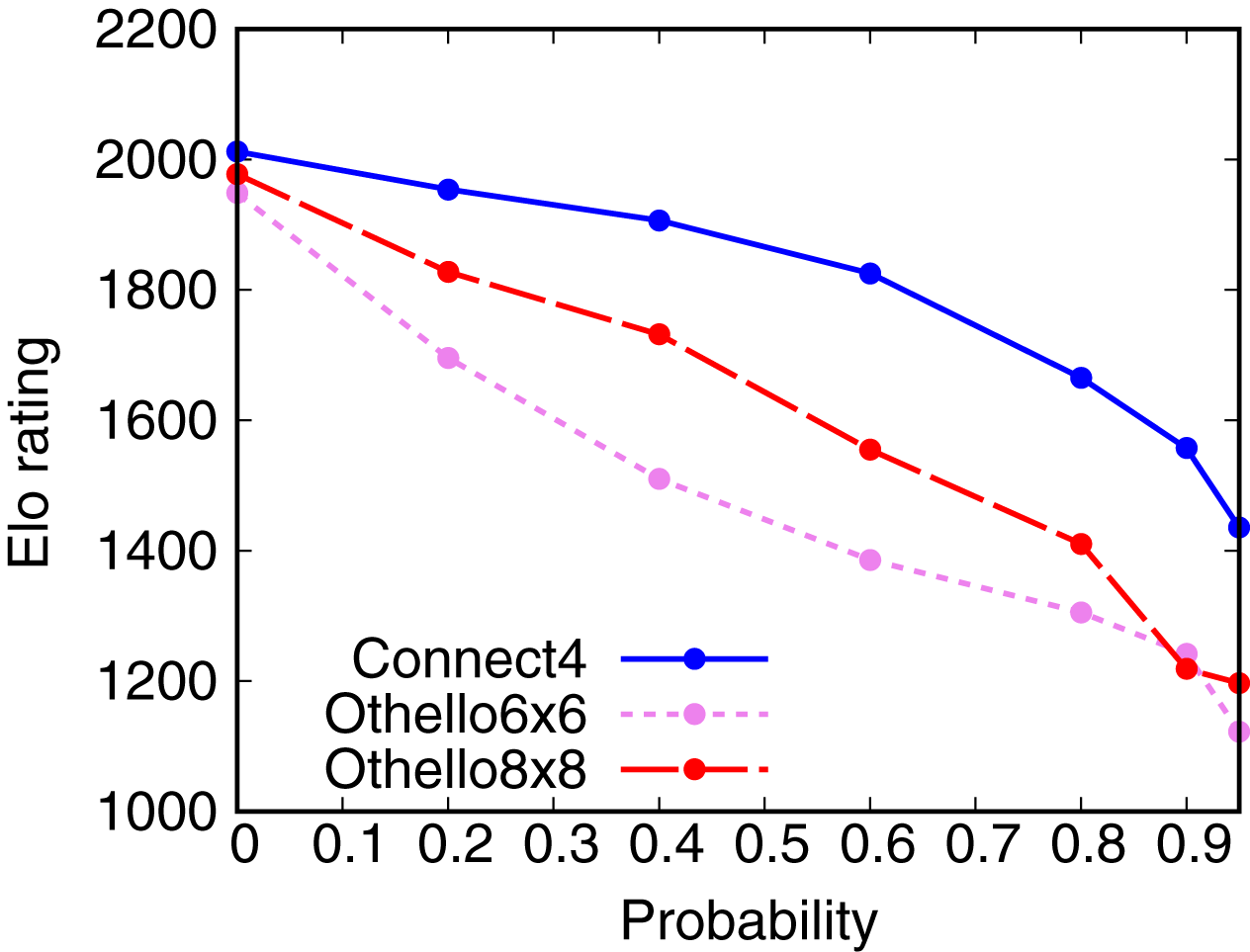
Combining Deep Reinforcement Learning and Search for Imperfect-Information Games

Multiplayer AlphaZero – arXiv Vanity
Alpha Zero / MuZero differences · Issue #143 · werner-duvaud/muzero-general · GitHub
Adversarial Search
AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]
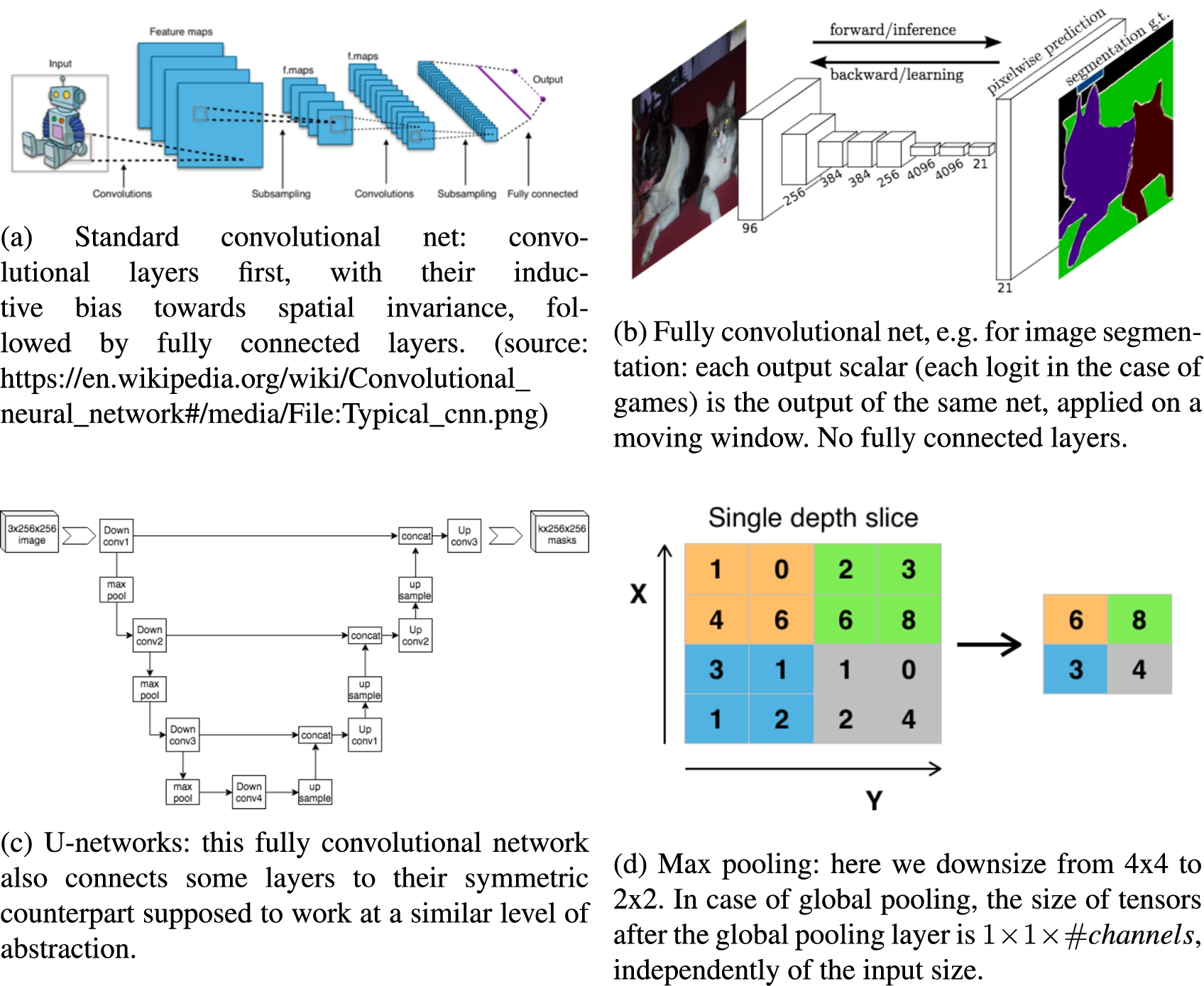
Deep learning for general game playing with Ludii and Polygames - IOS Press

DeepMind reveals more about MuZero, its A.I. that masters games without knowing the rules

Superhuman AI Triumphs Playing the Toughest Board Games

uttt.ai: AlphaZero-like AI self-play for Ultimate Tic-Tac-Toe with 100,000 simulations per move
Recomendado para você
-
 Deepmind's AlphaZero Plays Chess16 junho 2024
Deepmind's AlphaZero Plays Chess16 junho 2024 -
 AlphaZero - Notes on AI16 junho 2024
AlphaZero - Notes on AI16 junho 2024 -
 How AlphaZero Learns Chess16 junho 2024
How AlphaZero Learns Chess16 junho 2024 -
 DeepMind's AlphaZero crushes chess16 junho 2024
DeepMind's AlphaZero crushes chess16 junho 2024 -
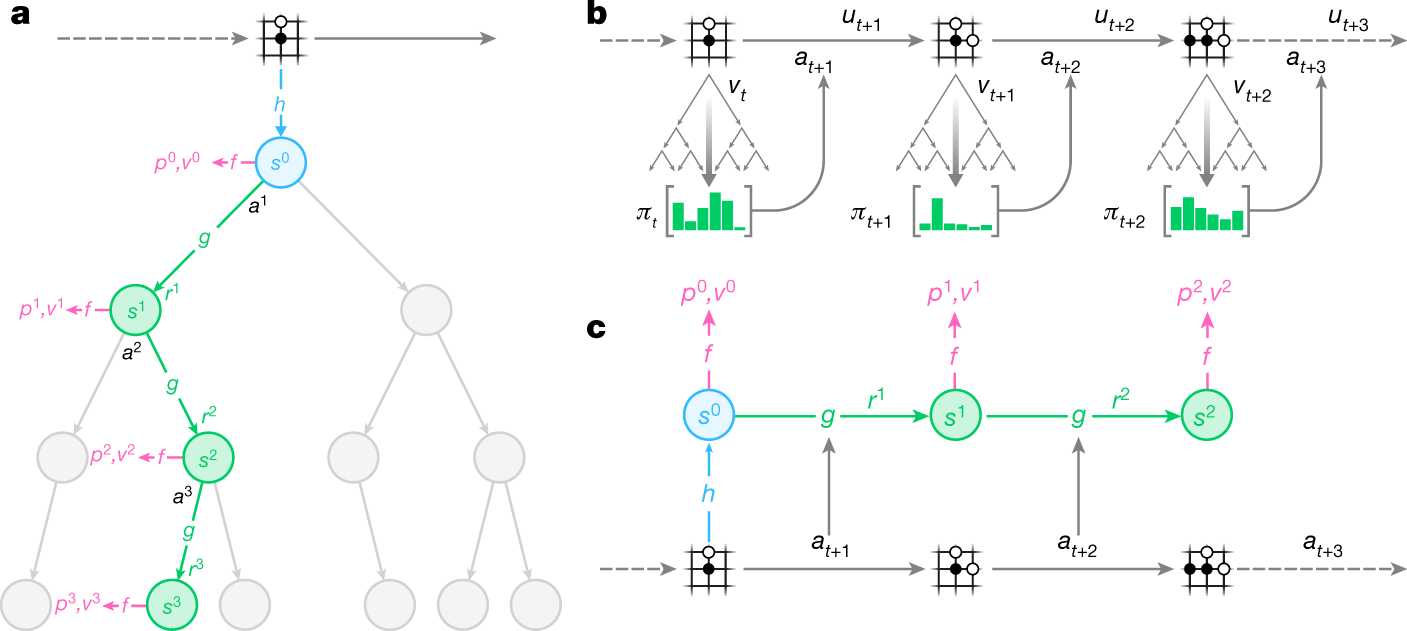 Mastering Atari, Go, chess and shogi by planning with a learned model16 junho 2024
Mastering Atari, Go, chess and shogi by planning with a learned model16 junho 2024 -
Cpuct is half of that in AlphaZero's paper? · Issue #694 · LeelaChessZero/lc0 · GitHub16 junho 2024
-
![PDF] Multiplayer AlphaZero](https://d3i71xaburhd42.cloudfront.net/be70e643641f62ed0e4d0db78b1120f8a79faafc/3-Figure1-1.png) PDF] Multiplayer AlphaZero16 junho 2024
PDF] Multiplayer AlphaZero16 junho 2024 -
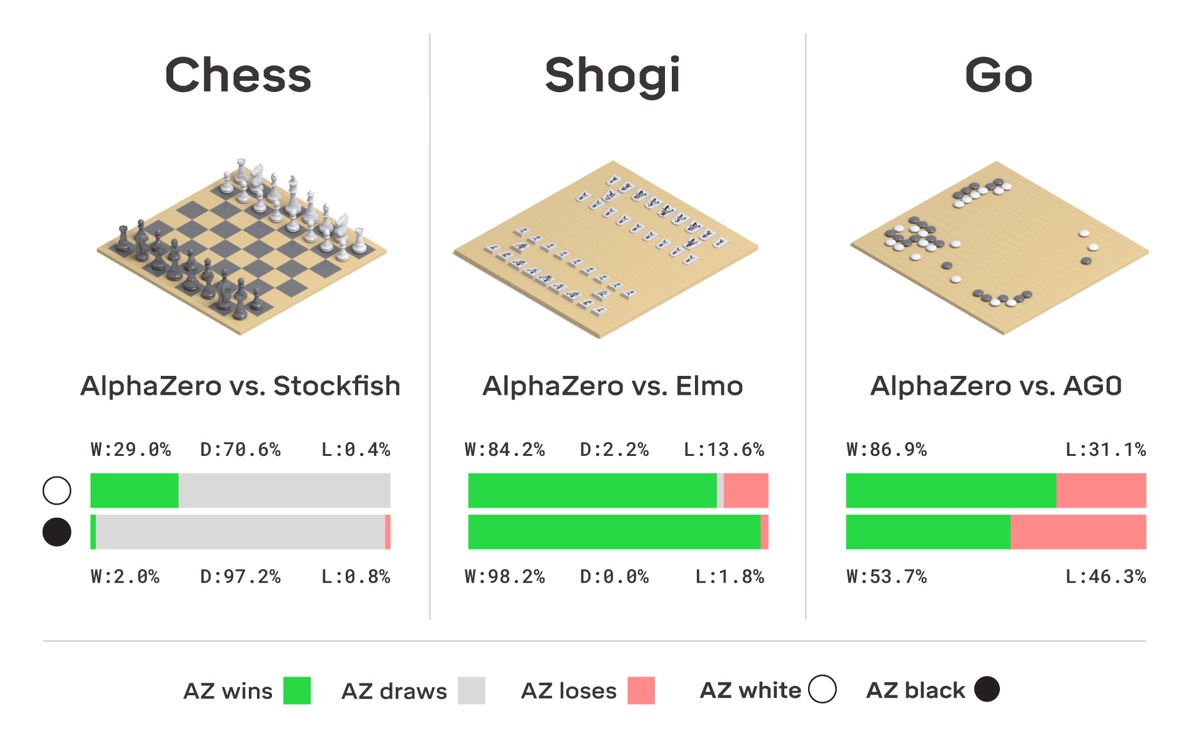 Move over AlphaGo: AlphaZero taught itself to play three different games16 junho 2024
Move over AlphaGo: AlphaZero taught itself to play three different games16 junho 2024 -
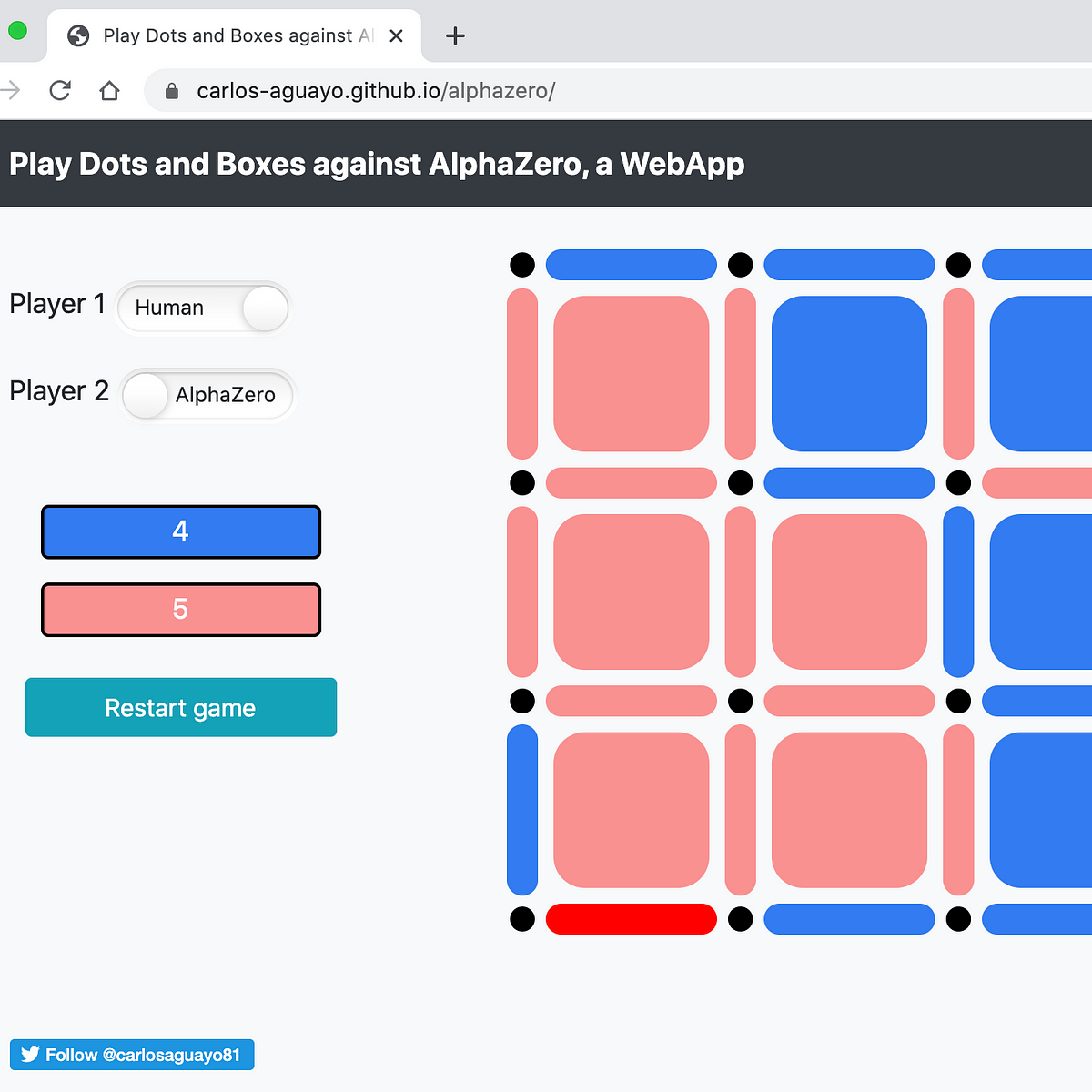 AlphaZero, a novel Reinforcement Learning Algorithm, in JavaScript, by Carlos Aguayo16 junho 2024
AlphaZero, a novel Reinforcement Learning Algorithm, in JavaScript, by Carlos Aguayo16 junho 2024 -
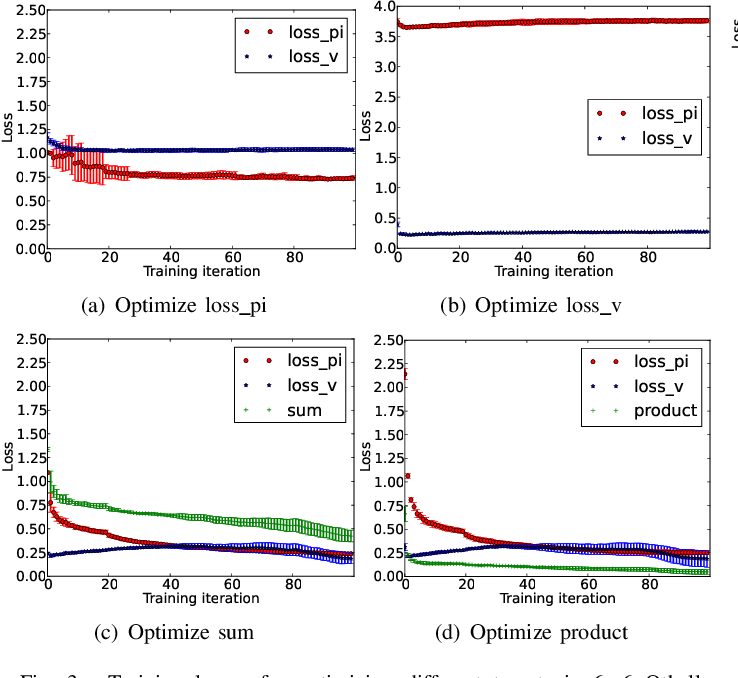 Policy or Value ? Loss Function and Playing Strength in AlphaZero-like Self-play16 junho 2024
Policy or Value ? Loss Function and Playing Strength in AlphaZero-like Self-play16 junho 2024
você pode gostar
-
 Who Is Meowbahh And What Is A PNGtuber?16 junho 2024
Who Is Meowbahh And What Is A PNGtuber?16 junho 2024 -
 Chess in India: Humpy and Harika on bridging the gap between women16 junho 2024
Chess in India: Humpy and Harika on bridging the gap between women16 junho 2024 -
Baldi's Basics Secret House 3D v1.0 APK Download16 junho 2024
-
 Jogos de Cobras e Escadas no Jogos 36016 junho 2024
Jogos de Cobras e Escadas no Jogos 36016 junho 2024 -
 Jet Hot Steam Splashes Image & Photo (Free Trial)16 junho 2024
Jet Hot Steam Splashes Image & Photo (Free Trial)16 junho 2024 -
 Can you name all of players from the Crystal Palace 2012/13 squad in six minutes?16 junho 2024
Can you name all of players from the Crystal Palace 2012/13 squad in six minutes?16 junho 2024 -
 Heavenly Delusion Anime's Main Promo Video Reveals April 1 Premiere, More Cast, Theme Song Artists - News - Anime News Network16 junho 2024
Heavenly Delusion Anime's Main Promo Video Reveals April 1 Premiere, More Cast, Theme Song Artists - News - Anime News Network16 junho 2024 -
 Let's Play Vampire: The Masquerade - Bloodlines - Part 1 - A Nosferatu playthrough16 junho 2024
Let's Play Vampire: The Masquerade - Bloodlines - Part 1 - A Nosferatu playthrough16 junho 2024 -
 Cómo dibujar a Pink de Rainbow Friends16 junho 2024
Cómo dibujar a Pink de Rainbow Friends16 junho 2024 -
 Steven Pressfield: 6 Ways to Take Your Passion to the Next Level16 junho 2024
Steven Pressfield: 6 Ways to Take Your Passion to the Next Level16 junho 2024
