RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
Por um escritor misterioso
Last updated 06 junho 2024

In this issue, we look at MuZero, DeepMind’s new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves state-of-the-art performance on Atari. We also look at Safety Gym, OpenAI’s new environment suite for safe RL.
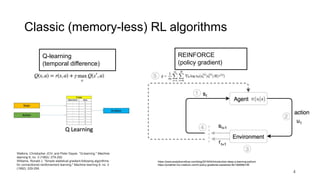
Memory for Lean Reinforcement Learning.pdf

PDF) A Review for Deep Reinforcement Learning in Atari:Benchmarks, Challenges, and Solutions
Summaries from arXiv e-Print archive on
RL Weekly 9: Sample-efficient Near-SOTA Model-based RL, Neural MMO, and Bottlenecks in Deep Q-Learning : r/reinforcementlearning

deep learning – Severely Theoretical
Aman's AI Journal • Papers List

PDF) Alpha-T: Learning to Traverse over Graphs with An AlphaZero-inspired Self-Play Framework

Memory for Lean Reinforcement Learning.pdf
RL Weekly 32: New SotA Sample Efficiency on Atari and an Analysis of the Benefits of Hierarchical RL

PDF) Model-free Reinforcement Learning with Stochastic Reward Stabilization for Recommender Systems
Recomendado para você
-
 Google DeepMind's new chess engine beats its famous AlphaZero06 junho 2024
Google DeepMind's new chess engine beats its famous AlphaZero06 junho 2024 -
 AlphaZero Explained06 junho 2024
AlphaZero Explained06 junho 2024 -
 Reimagining Chess with AlphaZero, February 202206 junho 2024
Reimagining Chess with AlphaZero, February 202206 junho 2024 -
 AQUACITY on X: AlphaZero's Unstoppable Journey! ♟🌟 Google's DeepMind AI has transformed the gaming world again, mastering chess in just 4 hours and taking down the champion program Stockfish 8! 🎲🏆 #AlphaZero #06 junho 2024
AQUACITY on X: AlphaZero's Unstoppable Journey! ♟🌟 Google's DeepMind AI has transformed the gaming world again, mastering chess in just 4 hours and taking down the champion program Stockfish 8! 🎲🏆 #AlphaZero #06 junho 2024 -
 AlphaZero AI system moves on from games to mathematics06 junho 2024
AlphaZero AI system moves on from games to mathematics06 junho 2024 -
 Lessons from AlphaZero for Optimal, by Dimitri P. Bertsekas06 junho 2024
Lessons from AlphaZero for Optimal, by Dimitri P. Bertsekas06 junho 2024 -
 Here comes the new and improved AlphaZero : r/chess06 junho 2024
Here comes the new and improved AlphaZero : r/chess06 junho 2024 -
How AlphaZero Completely CRUSHED Stockfish ( Part 10 ) #chess #gotha06 junho 2024
-
 DeepMind, Google Brain & World Chess Champion Explore How AlphaZero Learns Chess Knowledge06 junho 2024
DeepMind, Google Brain & World Chess Champion Explore How AlphaZero Learns Chess Knowledge06 junho 2024 -
 How the Artificial Intelligence Program AlphaZero Mastered Its06 junho 2024
How the Artificial Intelligence Program AlphaZero Mastered Its06 junho 2024

você pode gostar
-
 RuneScape money making: How to earn Gold fast - Dexerto06 junho 2024
RuneScape money making: How to earn Gold fast - Dexerto06 junho 2024 -
 Gerson Monteiro: “Triunfo cabo-verdiano não foi surpresa, e pode06 junho 2024
Gerson Monteiro: “Triunfo cabo-verdiano não foi surpresa, e pode06 junho 2024 -
 Como escolher plantas para ambientes fechados – Blog Metal Land06 junho 2024
Como escolher plantas para ambientes fechados – Blog Metal Land06 junho 2024 -
El gato and floppa best friends <3 #xyzbca #cat #elgato06 junho 2024
-
 Gran abierto blitz con la presencia del GM Ulf Andersson06 junho 2024
Gran abierto blitz con la presencia del GM Ulf Andersson06 junho 2024 -
 Abdul Zoldyck on X: BORUTO PART 2: BORUTO - TWO BLUE VORTEX06 junho 2024
Abdul Zoldyck on X: BORUTO PART 2: BORUTO - TWO BLUE VORTEX06 junho 2024 -
 Khaby Lame for Xbox: A TikTok Influencer's Foray Into Gaming06 junho 2024
Khaby Lame for Xbox: A TikTok Influencer's Foray Into Gaming06 junho 2024 -
 One Piece Episode 1049 Episode Guide – Release Date, Times & More - Cultured Vultures06 junho 2024
One Piece Episode 1049 Episode Guide – Release Date, Times & More - Cultured Vultures06 junho 2024 -
 Five Nights At Freddy's Animatronics Quiz - By JSavickas06 junho 2024
Five Nights At Freddy's Animatronics Quiz - By JSavickas06 junho 2024 -
 JOGOS DE HOJE - QUARTA FEIRA 25-01-23 / PROXIMOS JOGOS / ONDE06 junho 2024
JOGOS DE HOJE - QUARTA FEIRA 25-01-23 / PROXIMOS JOGOS / ONDE06 junho 2024
